
티스토리 뷰
본 포스팅은 “Deep Knowledge Tracing” 논문의 주요 내용을 정리하였습니다.
[논문 링크] https://arxiv.org/abs/1506.05908
Deep Knowledge Tracing
Knowledge tracing---where a machine models the knowledge of a student as they interact with coursework---is a well established problem in computer supported education. Though effectively modeling student knowledge would have high educational impact, the ta
arxiv.org
1. Knowledge Tracing(지식 추적) 이란 ?
- 학습자의 정오답 데이터를 이용해 학습자의 지식 수준을 모델링 하는 것
- 주요 키워드 : KT(Knowledge Tracing) , RNN, LSTM

2. 어떤 문제를 해결하려고 하는가?
- 인공신경망을 이용한 시간에 따른 학습자들의 잠재적 지식 상태 표현
- 기존의 룰 기반의 방법 or 전문가의 주석에 의존하는 것이 아닌 데이터 기반 학습을 통한 학습자들의 지식 상태 표현
- 딥러닝 알고리즘을 이용한 성능 개선
- 전문가의 주석이 필요하지 않음 --> 주석이 없는 상태에서 자동으로 문제 인덱스의 구조를 학습 가능
- 기존 KT 알고리즘으로 BKT 소개
- BKT(Bayesian Knowledge Tracing) : 학습자의 잠재 지식 상태를 Binary 변수들의 모음으로 설정하고, 각각의 변수는 하나 문제 인덱스 (태그)에 대한 이해/이해 못함으로 나타냄
- (한계점) 학생의 이해도에 대한 binary 표현은 현실적이지 않으며, 문제 하나에 한가지 개념만으로 매칭 되는 경우가 적으므로 현실적인 맞지 않음
3. 모델 (Deep Knowledge Tracing)
- 두가지 접근 방식
- Vanilla RNN 모델 with Sigmoid
- Long Short Term Memory (LSTM)
- RNN을 통해 사용자의 문제 인덱스별 정오답 데이터 (학습수준)이 학습되고, 이후 사용자가 풀지 않은 문제들에 대한 정오답 확률을 에측하는 것
- 입력 데이터
- 학생 상호작용에 대해 RNN 또는 LSTM을 훈련하려면, 이러한 상호작용을 고정 길이 입력 벡터의 xt의 시퀀스로 변환해야 함
- one-hot encoding 형식 (임베딩 구축 방법)
- 상호작용의 표현은 일반적으로 상호작용 인덱스를 정의하여, 상호작용 인덱스는 일반적으로 다음과 같이 정의
- 최적화 (Optimization)
- 학습의 목적은, 학생의 관측된 순서의 음의 로그 우도 함수
- 로그 우도 함수 : https://airsbigdata.tistory.com/202 참고
(참고) https://yun905.tistory.com/24
δ(qt+1) = t+1 시간의 one-hot encoding
l = binary cross entropy (두 확률 분포 p,q 사이에 존재하는 정보량을 계산하는 방법)
one-hot 벡터가 t번째 timestamp의 y벡터와 곱해지면서,y 예측값 중 t+1 번째 q에 해당하는 값만 남기고 나머지예측값을 0으로 만든다.
4. educational Application
- 학생의 과거 활동을 통해, 미래의 실력을 예측하는 것
- 커리큘럼 개선
- 학습자의 지식 수준을 향상 시키기 위한 문제를 추천 해줄 수 있음
예시를 보면, 51번째 어떤 문제를 풀어야 학생의 지식 수준이 향상될지를 예측할 수 있음
51번째 문제로, y-intercept (y 절편)으로 문제를 풀어서 맞았다는 정보를 넣어 준 뒤, 모델의 output인 y 벡터를 시각화한 결과, 기존의 파란색이 학습자가 잘 맞추지 못하던 문제도 정답을 맞출 확률이 높아졌고, 따라서 지식 수준이 향상될 것임을 예상할 수 있음
- 문제 간의 관계를 찾는 것
- i 문제를 푼 뒤, j 문제를 풀었을 때, 정답을 맞출 확률을 위와 같이 정의
- i를 풀고, j를 풀었을 대 맞출 확률이 높다는 의미로 다시 말해 i 문제가 j 문제의 선수 지식을 다루고 있다고 가정
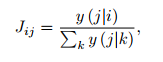
5. 실험
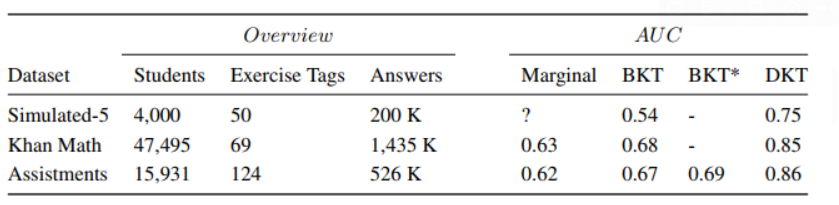
- 시뮬레이션 데이터 : 2000명 학생이 동일한 순서의 50개 문제의 정오답
- Khan Math : 47,495명의 69개(태그) 문제의 정오답
- Assistments 2009-2010 Skill builder 공개 데이터셋
- 결과
- AUC 기준으로, 기존 BKT 알고리즘에 비해 성능 향상 (BKT: 0.68 --> DKT: 0.85)
6. 결론
- KT 모델에 RNN/LSTM을 적용한 결과, Assistment, Khan 데이터 세트에서 이전 성능보다 향상된 성능을 보임
- 전문가 주석이 필요하지 않고, 자체적으로 개념의 구조(관계)를 학습할 수 있음
- 벡터화할 수 있는 모든 학생 입력에 대해 작동
- 단점은, 많은 양의 훈련 데이터가 필요하기 때문에 온라인 교육 환경에는 적합하지만, 소규모 교실 환경에는 적합하지 않음
- 향후 방향
- 입력으로 다른 변수 (예: 소요시간) 추가
- 다른 교육적 영향 (예:이탈 예측)을 탐색하고, 교육 문헌에 제기된 가설 (간격 반복, 학생들이 잊는 방식 모델링)을 검증
'추천시스템' 카테고리의 다른 글
| [추천 모델 리뷰] Learning To Rank (LTR) (0) | 2022.10.02 |
|---|---|
| [추천 논문 리뷰] Session based recommendations with recurrent neural network (0) | 2022.07.24 |
| [추천 논문 리뷰] Neural Collaborative Filtering (0) | 2022.06.26 |